
王中王72385.cσm查询单双八尾精选解释解析落实
在当今信息爆炸的时代,数据分析已成为各行各业不可或缺的一部分,尤其是在彩票行业,我们将深入探讨一个特定的在线平台——王中王72385.cσm,特别是其提供的“单双八尾”查询服务,本文将详细解析这一功能的背景、应用及其背后的统计学原理,旨在为读者提供一个全面而深入的理解。
一、王中王72385.cσm平台概述
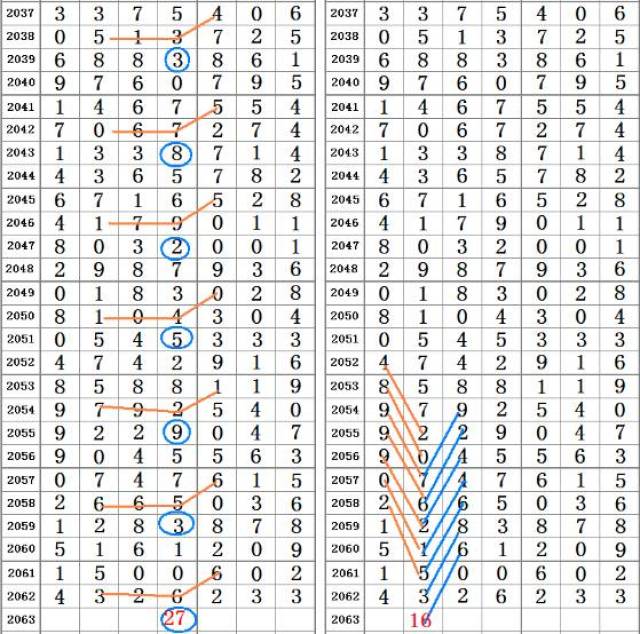
王中王72385.cσm是一个专注于彩票数据分析与预测的在线平台,提供多种彩票相关的数据查询和分析工具,帮助用户做出更为理性的投注决策。“单双八尾”查询是该平台的一项特色功能,专门针对某种特定类型的彩票玩法设计,用以预测下一期开奖号码的单双属性及最后一位数字(即“尾数”)的走势。
二、何为“单双八尾”?
在解释“单双八尾”之前,需要明确两个概念:“单双”和“尾数”。
- “单双”指的是数字的奇偶性,在彩票中,通常根据开奖号码的最后一位来判断,若为1, 3, 5, 7, 9则为单(奇数),2, 4, 6, 8, 0则为双(偶数)。
- “尾数”则是指开奖号码的最后一位数,如果开奖结果为1234,尾数”就是4。
“单双八尾”因此得名,它结合了这两个维度:既考虑号码的单双属性,也关注尾数的变化规律。
三、统计学原理与数据分析方法
1. 概率论基础
任何彩票游戏的核心都是概率,理解“单双八尾”首先需要掌握基本的概率论知识,理论上,每个位置上的数字出现的概率是相等的,即从0到9中的任意一个数字都有相同的可能性成为尾数,单双出现的概率也应接近50%,实际开奖历史数据往往显示出一定的偏差和模式,这正是分析师试图通过数据分析捕捉的。
2. 历史数据分析
通过对过往开奖数据的收集与整理,分析师可以构建数据集,进而运用统计学方法如频率分析、趋势分析等,来识别“单双”和“尾数”出现的模式,可能会发现某些时间段内“单”数特别频繁,或者特定的尾数如“8”出现的概率高于其他数字。
3. 条件概率与贝叶斯定理
进一步地,分析师可能会采用条件概率的概念,即基于已知的某些条件下,计算特定结果发生的概率,贝叶斯定理在这里非常有用,它可以帮助分析师根据新的证据更新他们对某一事件发生概率的估计,比如在前几期连续出现“单”数后,下一期出现“双”的条件概率变化。
四、实际应用与案例分析
1. 数据收集与预处理
使用Python编程语言及其强大的数据处理库(如Pandas和NumPy),首先从王中王72385.cσm平台或其他可靠数据源爬取历史开奖数据,数据清洗步骤包括去除无效或缺失值、转换数据格式以及标准化数值范围等,确保后续分析的准确性。
import pandas as pd
import numpy as np
示例:加载数据
data = pd.read_csv('lottery_data.csv')
数据清洗
data = data.dropna() # 删除缺失值
data['last_digit'] = data['winning_number'].apply(lambda x: int(x) % 10) # 计算尾数
data['odd_even'] = data['last_digit'].apply(lambda x: 'Odd' if x % 2 != 0 else 'Even') # 判断单双2. 探索性数据分析(EDA)
利用Matplotlib和Seaborn等可视化工具进行初步的数据探索,绘制尾数和单双属性的频率分布图、时间序列图等,直观展示数据特征。
import matplotlib.pyplot as plt
import seaborn as sns
绘制尾数分布
sns.histplot(data['last_digit'], kde=True)
plt.title('Distribution of Last Digit')
plt.show()
绘制单双比例随时间变化
sns.lineplot(data='date', y='odd_even_count', hue='odd_even', data=data)
plt.title('Odd/Even Trend Over Time')
plt.show()3. 建立预测模型
基于历史数据,可以使用机器学习算法如逻辑回归、随机森林或梯度提升机等来构建预测模型,以尾数预测为例,输入特征可能包括历史尾数、单双属性、日期等,目标变量即为下一期的尾数或单双属性。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
准备特征和标签
X = data[['last_digit', 'is_odd']]
y = data['next_last_digit']
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
训练模型
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
预测与评估
predictions = clf.predict(X_test)
print(f'Accuracy: {accuracy_score(y_test, predictions)}')4. 交叉验证与超参数调优
为了提高模型的泛化能力,应进行交叉验证,并通过网格搜索等方法优化模型参数。
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [10, 20, 30]
}
grid_search = GridSearchCV(estimator=clf, param_grid=param_grid, cv=5)
grid_search.fit(X_train, y_train)
print(f'Best parameters: {grid_search.best_params_}')
print(f'Best cross-validated score: {grid_search.best_score_}')通过对王中王72385.cσm平台上“单双八尾”查询功能的深入分析,我们不仅揭示了其背后的统计学原理和数据分析方法,还展示了如何利用现代数据科学技术进行有效的预测,值得注意的是,尽管数据分析能够揭示一定的规律和趋势,但彩票本质上仍是一种随机事件,没有任何方法能保证百分之百的预测准确率,建议用户在使用此类分析工具时应保持理性态度,将其作为参考而非决策的唯一依据。
持续监测模型性能、定期更新数据和调整策略也是维持预测有效性的关键,对于开发者而言,不断优化算法、提高预测精度和用户体验将是提升平台竞争力的重要途径。
转载请注明来自扎嘎圣山景区,本文标题:《王中王72385.cσm查询单双八尾|精选解释解析落实》






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号